1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| import os
import time
import requests
from bs4 import BeautifulSoup
import re
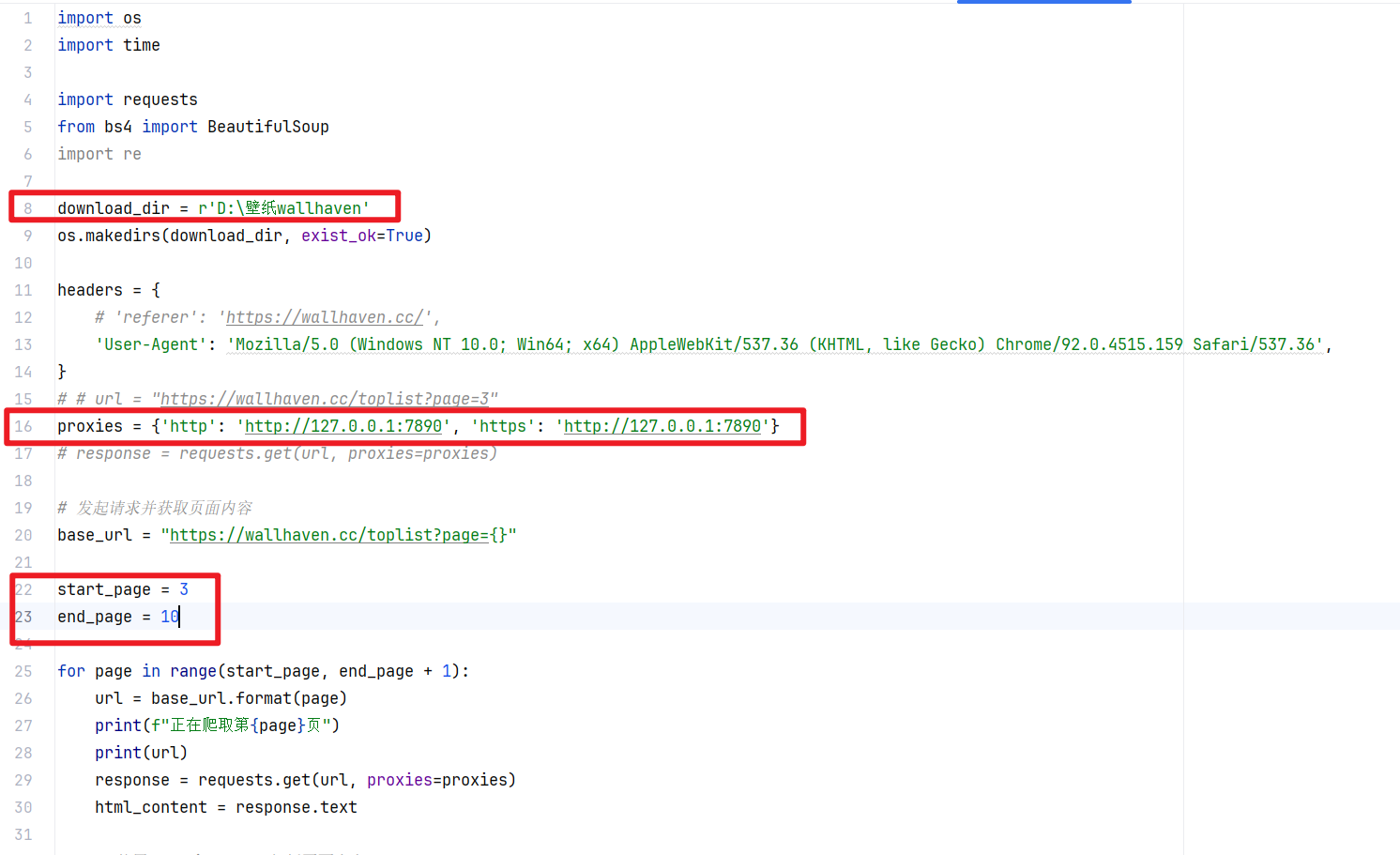
download_dir = r'D:\壁纸wallhaven'
os.makedirs(download_dir, exist_ok=True)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
base_url = "https://wallhaven.cc/toplist?page={}"
start_page = 3
end_page = 10
for page in range(start_page, end_page + 1):
url = base_url.format(page)
print(f"正在爬取第{page}页")
print(url)
response = requests.get(url, proxies=proxies)
html_content = response.text
soup = BeautifulSoup(html_content, "html.parser")
preview_links = soup.find_all("a", class_="preview")
for link in preview_links:
href = link.get("href")
print("======================================")
print(href)
time.sleep(1)
try:
response_2 = requests.get(href, proxies=proxies)
soup = BeautifulSoup(response_2.text, "html.parser")
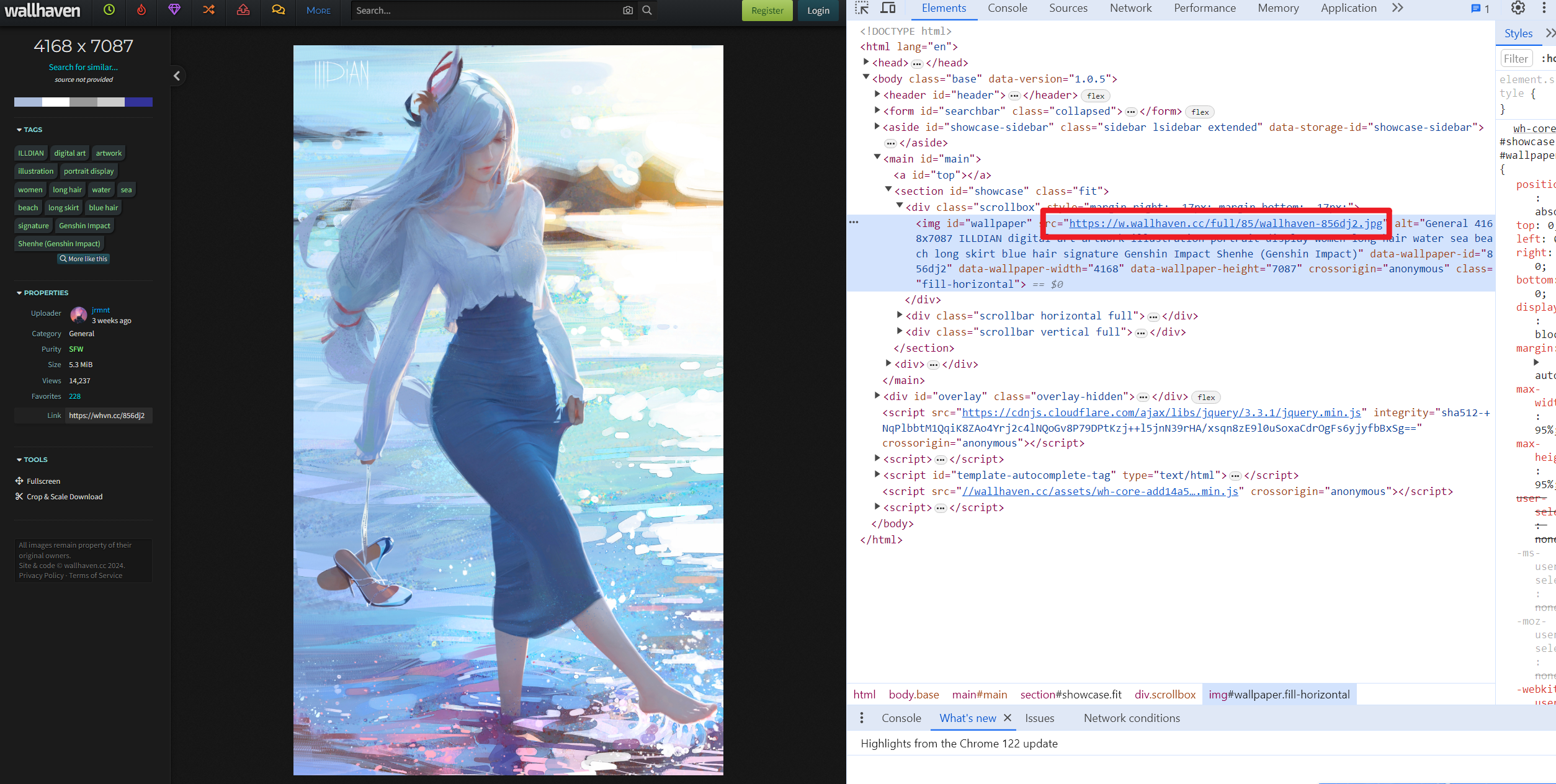
wallpaper_img = soup.find("img", id="wallpaper")
src_link = wallpaper_img.get("src")
print(src_link)
file_name = src_link.split("/")[-1]
print(file_name)
response = requests.get(src_link, proxies=proxies)
if response.status_code == 200:
with open(os.path.join(download_dir, f"{file_name}"), "wb") as f:
f.write(response.content)
print("图片下载成功!" + src_link)
else:
print("下载失败,状态码:", response.status_code, '"', src_link, '"')
except Exception as e:
print("爬取失败:", e)
continue
|