深度学习-李沐-第十三节-锚框
锚框
以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。 这些边界框被称为锚框(anchor box)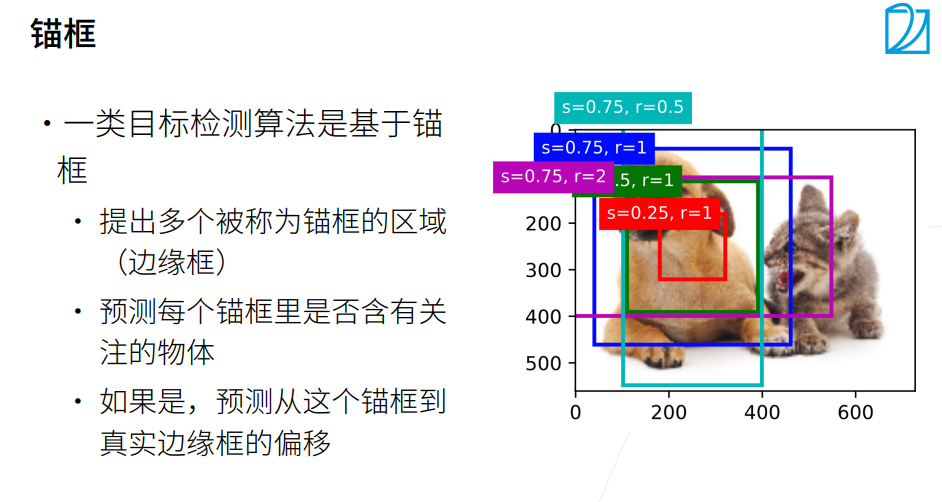
生成多个锚框

指定输入图像、尺寸列表和宽高比列表,然后此函数将返回所有的锚框
1 | #@save |
1 | img = d2l.plt.imread('../img/catdog.jpg') |

访问以(250,250)为中心的第一个锚框。 它有四个元素:锚框左上角的轴坐标和右下角的轴坐标。 将两个轴的坐标各分别除以图像的宽度和高度后,所得的值介于0和1之间。
1 | boxes = Y.reshape(h, w, 5, 4) |
绘制多个边界框
1 | #@save |
1 | d2l.set_figsize() |
交并比(IoU)

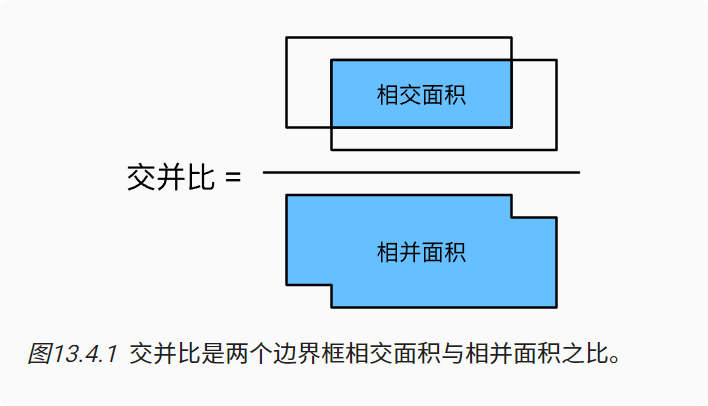
使用交并比来衡量锚框和真实边界框之间、以及不同锚框之间的相似度 给定两个锚框或边界框的列表,以下box_iou函数将在这两个列表中计算它们成对的交并比。
1 | #@save |
标注锚框
- 在训练集中,我们将每个锚框视为一个训练样本
- 为了训练目标检测模型,我们需要每个锚框的类别(class)和偏移量(offset)标签
- 类别是与锚框相关的对象的类别,偏移量是真实边界框相对于锚框的偏移量
- 为每个图像生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后只输出符合特定条件的预测边界框
1 | #@save |
使用非极大值抑制预测边界框

将锚框和偏移量预测作为输入,并应用逆偏移变换来返回预测的边界框坐标。
1 | #@save |

1 | #@save |
假设预测的偏移量都是零,这意味着预测的边界框即是锚框。 对于背景、狗和猫其中的每个类,我们还定义了它的预测概率。
1 | anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95], |
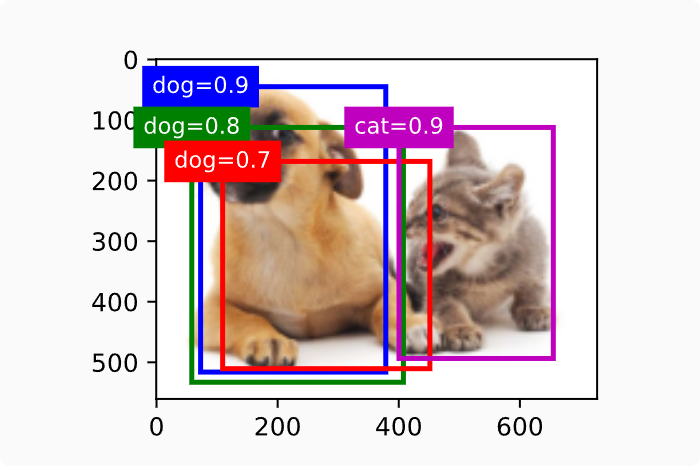
调用multibox_detection函数来执行非极大值抑制,其中阈值设置为0.5。
返回结果的形状是(批量大小,锚框的数量,6)。 最内层维度中的六个元素提供了同一预测边界框的输出信息。 第一个元素是预测的类索引,从0开始(0代表狗,1代表猫),值-1表示背景或在非极大值抑制中被移除了。 第二个元素是预测的边界框的置信度。 其余四个元素分别是预测边界框左上角和右下角的轴坐标(范围介于0和1之间)。
删除-1类别(背景)的预测边界框后,我们可以输出由非极大值抑制保存的最终预测边界框
1 | fig = d2l.plt.imshow(img) |
小结
我们以图像的每个像素为中心生成不同形状的锚框。
交并比(IoU)也被称为杰卡德系数,用于衡量两个边界框的相似性。它是相交面积与相并面积的比率。
在训练集中,我们需要给每个锚框两种类型的标签。一个是与锚框中目标检测的类别,另一个是锚框真实相对于边界框的偏移量。
在预测期间,我们可以使用非极大值抑制(NMS)来移除类似的预测边界框,从而简化输出。
- 标题: 深度学习-李沐-第十三节-锚框
- 作者: moye
- 创建于 : 2022-08-16 15:00:46
- 更新于 : 2025-12-12 18:22:53
- 链接: https://www.kanes.top/2022/08/16/深度学习-李沐-第十三节-锚框/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。