深度学习-李沐-第十三节-常用图像增广方法
图像增广
常用图像增广方法
1 | d2l.set_figsize() |
翻转和裁剪


apply(img, torchvision.transforms.RandomHorizontalFlip())
apply(img, torchvision.transforms.RandomVerticalFlip())
1 | shape_aug = torchvision.transforms.RandomResizedCrop( |

改变颜色
apply(img, torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0))
color_aug = torchvision.transforms.ColorJitter( brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5) apply(img, color_aug)
训练
1 | #@save |
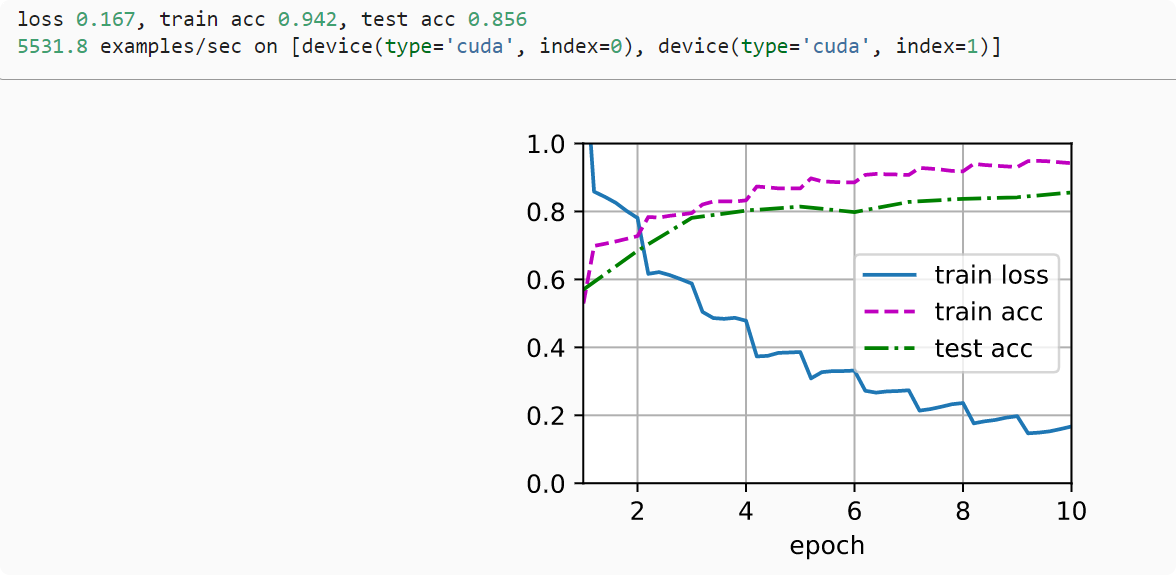
小结
图像增广基于现有的训练数据生成随机图像,来提高模型的泛化能力。
为了在预测过程中得到确切的结果,我们通常对训练样本只进行图像增广,而在预测过程中不使用带随机操作的图像增广。
深度学习框架提供了许多不同的图像增广方法,这些方法可以被同时应用。
- 标题: 深度学习-李沐-第十三节-常用图像增广方法
- 作者: moye
- 创建于 : 2022-08-16 15:00:46
- 更新于 : 2025-12-12 18:22:53
- 链接: https://www.kanes.top/2022/08/16/深度学习-李沐-第十三节-常用图像增广方法/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
评论