深度学习-李沐-第六节-汇聚层与卷积神经网络LeNet
汇聚层与卷积神经网络LeNet
汇聚层
双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
最大汇聚层和平均汇聚层
与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。 不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。 相反,池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)。
在这两种情况下,与互相关运算符一样,汇聚窗口从输入张量的左上角开始,从左往右、从上往下的在输入张量内滑动。在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的最大值或平均值。计算最大值或平均值是取决于使用了最大汇聚层还是平均汇聚层。
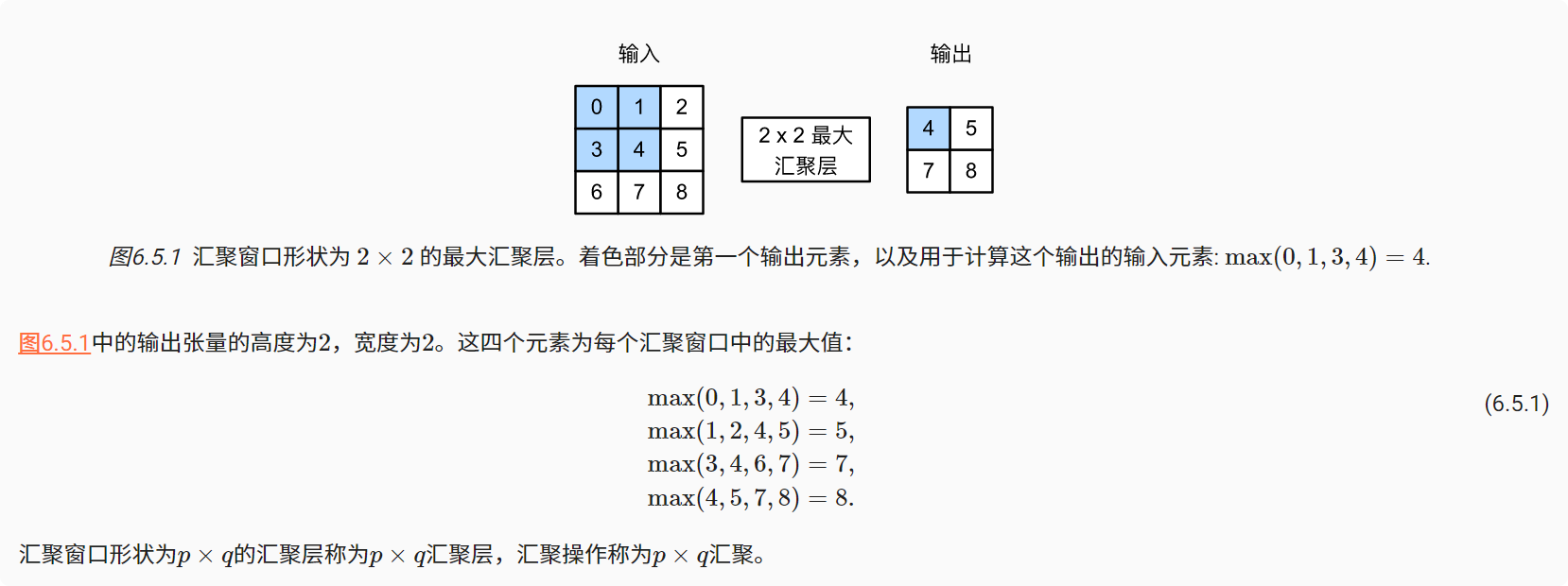
设置卷积层输入为X,汇聚层输出为Y。 无论X[i, j]和X[i, j + 1]的值相同与否,或X[i, j + 1]和X[i, j + 2]的值相同与否,汇聚层始终输出Y[i, j] = 1。 也就是说,使用最大汇聚层,即使在高度或宽度上移动一个元素,卷积层仍然可以识别到模式。
1 | import torch |
汇聚层的填充、步幅、多通道
与卷积层一样,汇聚层也可以改变输出形状。
1 | X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4)) |
在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总
汇聚层的输出通道数与输入通道数相同。
汇聚层小结
- 对于给定输入元素,最大汇聚层会输出该窗口内的最大值,平均汇聚层会输出该窗口内的平均值。
- 汇聚层的主要优点之一是减轻卷积层对位置的过度敏感。
- 我们可以指定汇聚层的填充和步幅。
- 使用最大汇聚层以及大于1的步幅,可减少空间维度(如高度和宽度)。
- 汇聚层的输出通道数与输入通道数相同。
卷积神经网络LeNet
为了能够应用softmax回归和多层感知机,我们首先将每个大小为的图像展平为一个784维的固定长度的一维向量,然后用全连接层对其进行处理。 而现在,我们已经掌握了卷积层的处理方法,我们可以在图像中保留空间结构。 同时,用卷积层代替全连接层的另一个好处是:模型更简洁、所需的参数更少。
LeNet
组成:
- 卷积编码器:由两个卷积层组成;
- 全连接层密集块:由三个全连接层组成。
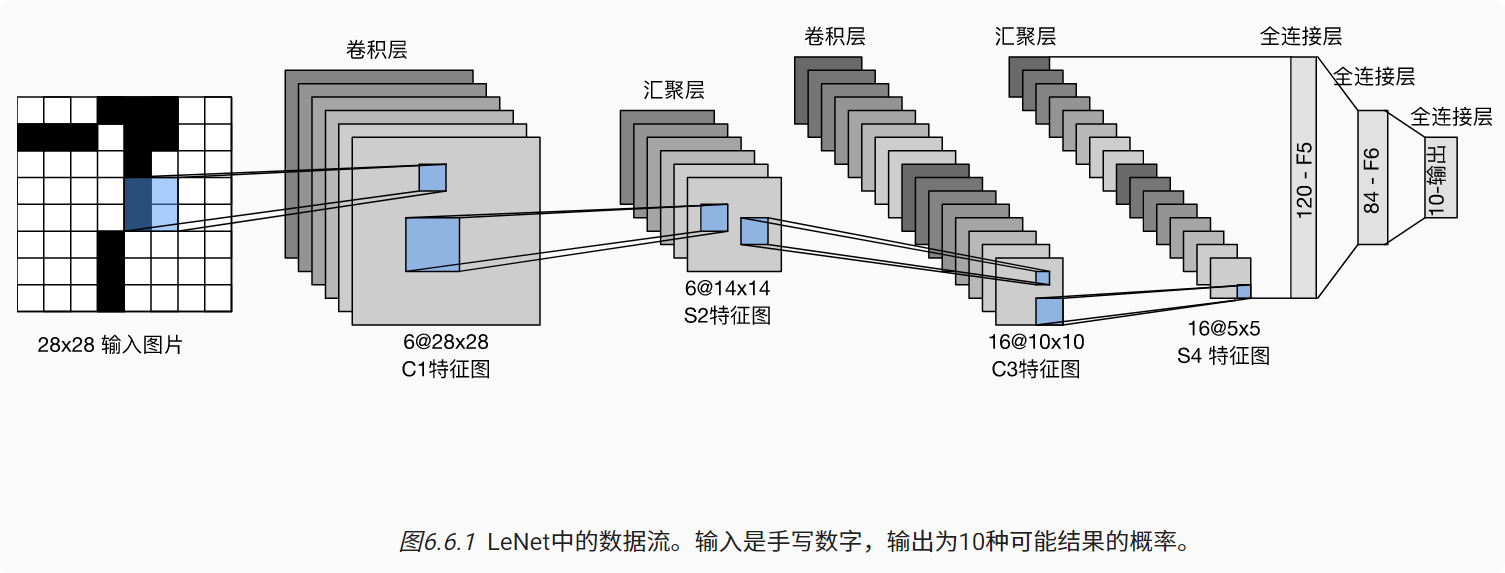
每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。
这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。
每个2×2池操作(步骤2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。
换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量。
1 | import torch |
LeNet小结
卷积神经网络(CNN)是一类使用卷积层的网络。
在卷积神经网络中,我们组合使用卷积层、非线性激活函数和汇聚层。
为了构造高性能的卷积神经网络,我们通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数。
在传统的卷积神经网络中,卷积块编码得到的表征在输出之前需由一个或多个全连接层进行处理。
LeNet是最早发布的卷积神经网络之一。
- 标题: 深度学习-李沐-第六节-汇聚层与卷积神经网络LeNet
- 作者: moye
- 创建于 : 2022-08-16 15:00:46
- 更新于 : 2025-12-12 18:22:53
- 链接: https://www.kanes.top/2022/08/16/深度学习-李沐-第六节-汇聚层与卷积神经网络LeNet/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。